Get started
Sign up and create an API key
An API key authenticates your machine to W&B. You can generate an API key from your user profile.For a more streamlined approach, create an API key by going directly to User Settings. Copy the newly created API key immediately and save it in a secure location such as a password manager.
- Click your user profile icon in the upper right corner.
- Select User Settings, then scroll to the API Keys section.
Install the wandb library and log in
To install the wandb library locally and log in:
- Command Line
- Python
- Python notebook
-
Set the
WANDB_API_KEYenvironment variable to your API key. -
Install the
wandblibrary and log in.
Log metrics
Make plots
Step 1: Import wandb and initialize a new run
Step 2: Visualize plots
Individual plots
After training a model and making predictions you can then generate plots in wandb to analyze your predictions. See the Supported Plots section below for a full list of supported charts.All plots
W&B has functions such asplot_classifier that will plot several relevant plots:
Existing Matplotlib plots
Plots created on Matplotlib can also be logged on W&B Dashboard. To do that, it is first required to installplotly.
Supported plots
Learning curve
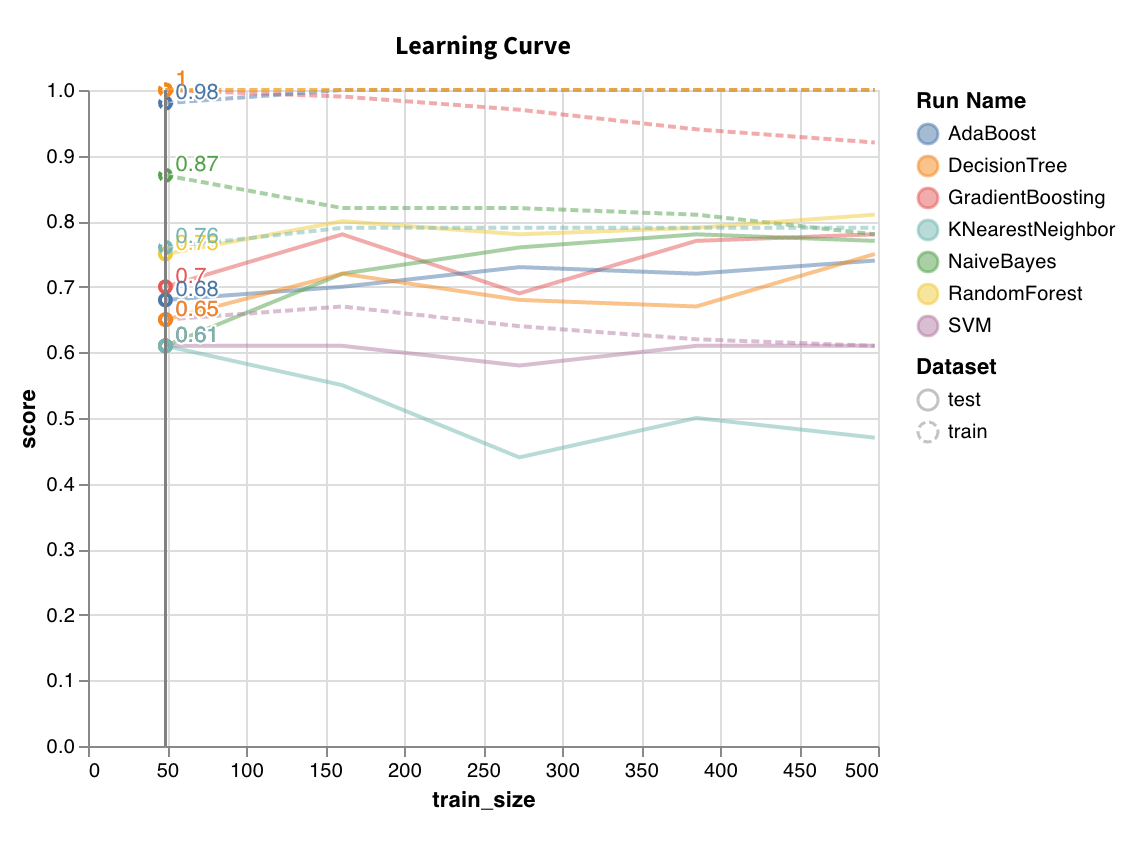
wandb.sklearn.plot_learning_curve(model, X, y)
- model (clf or reg): Takes in a fitted regressor or classifier.
- X (arr): Dataset features.
- y (arr): Dataset labels.
ROC
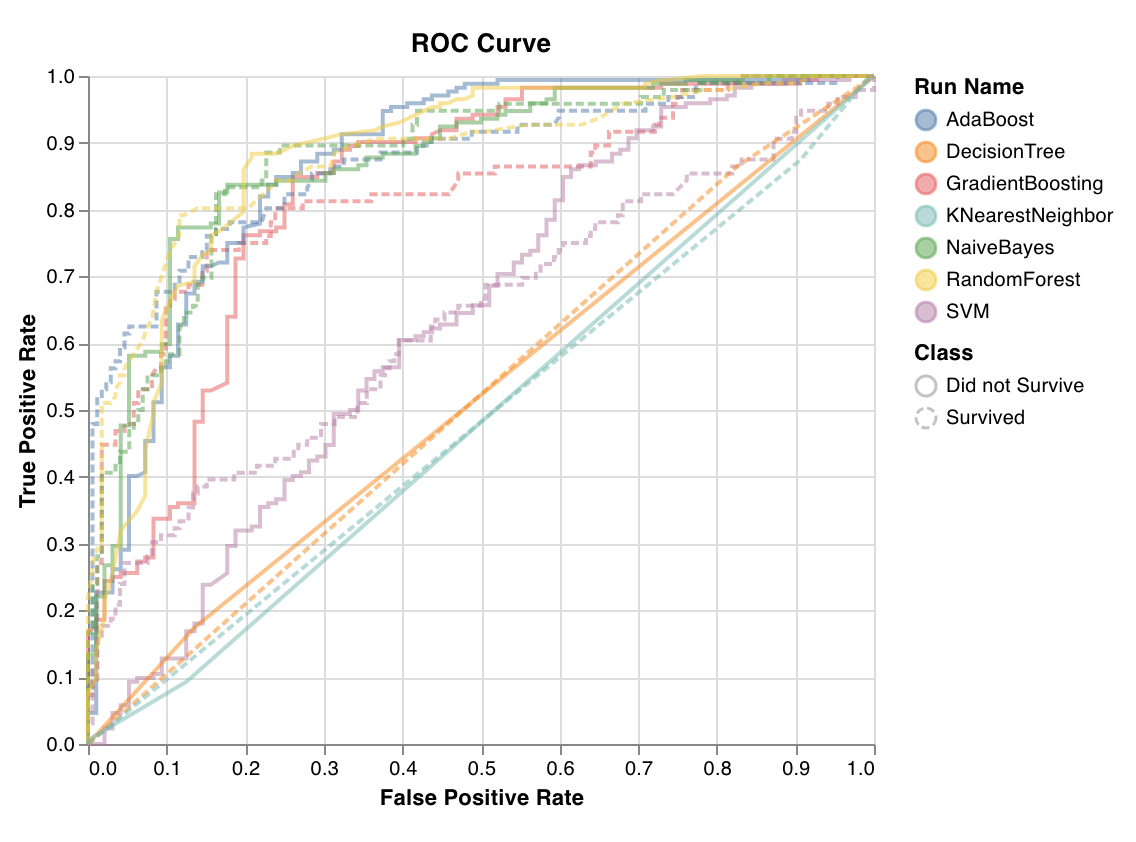
wandb.sklearn.plot_roc(y_true, y_probas, labels)
- y_true (arr): Test set labels.
- y_probas (arr): Test set predicted probabilities.
- labels (list): Named labels for target variable (y).
Class proportions
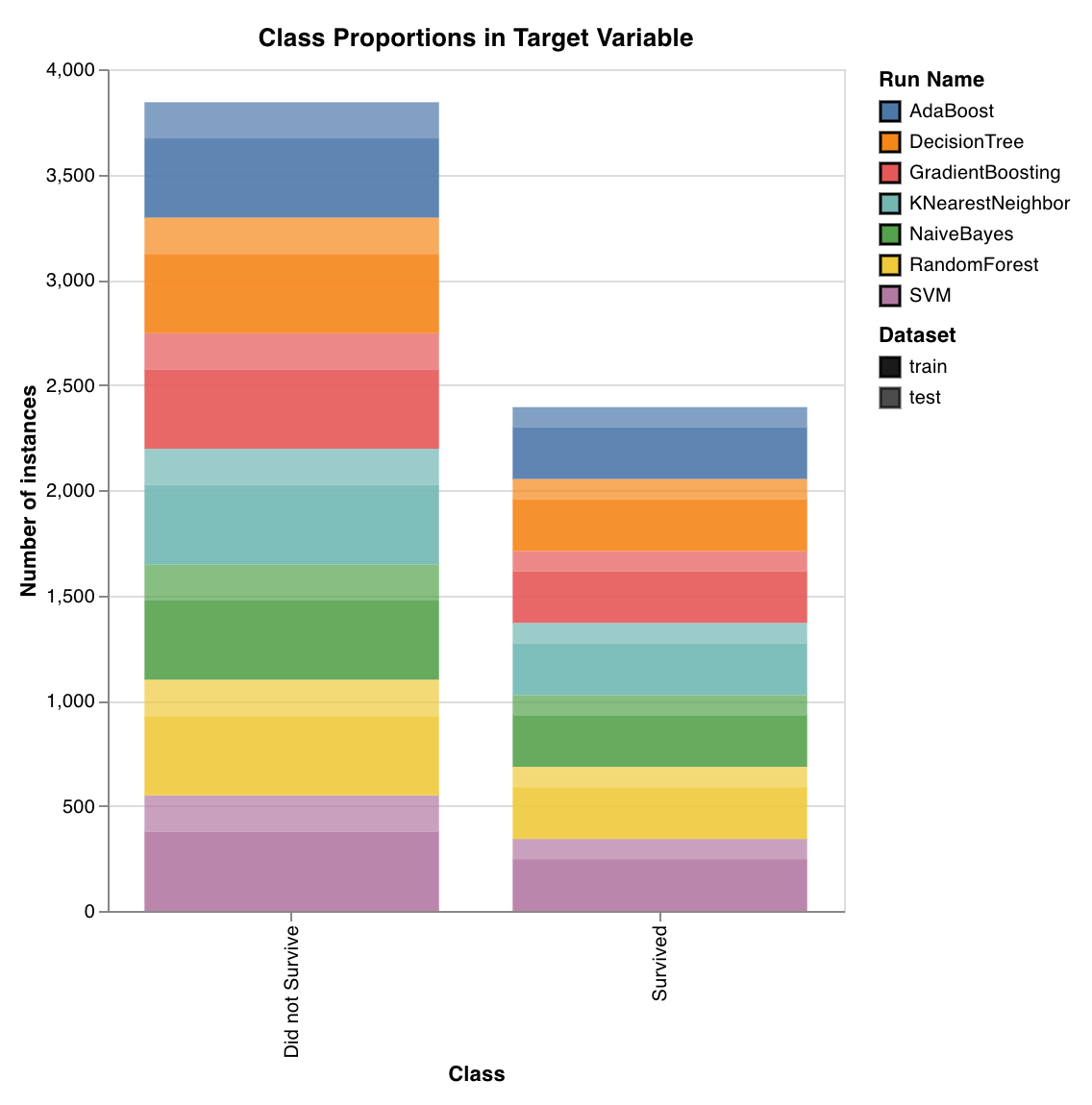
wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])
- y_train (arr): Training set labels.
- y_test (arr): Test set labels.
- labels (list): Named labels for target variable (y).
Precision recall curve
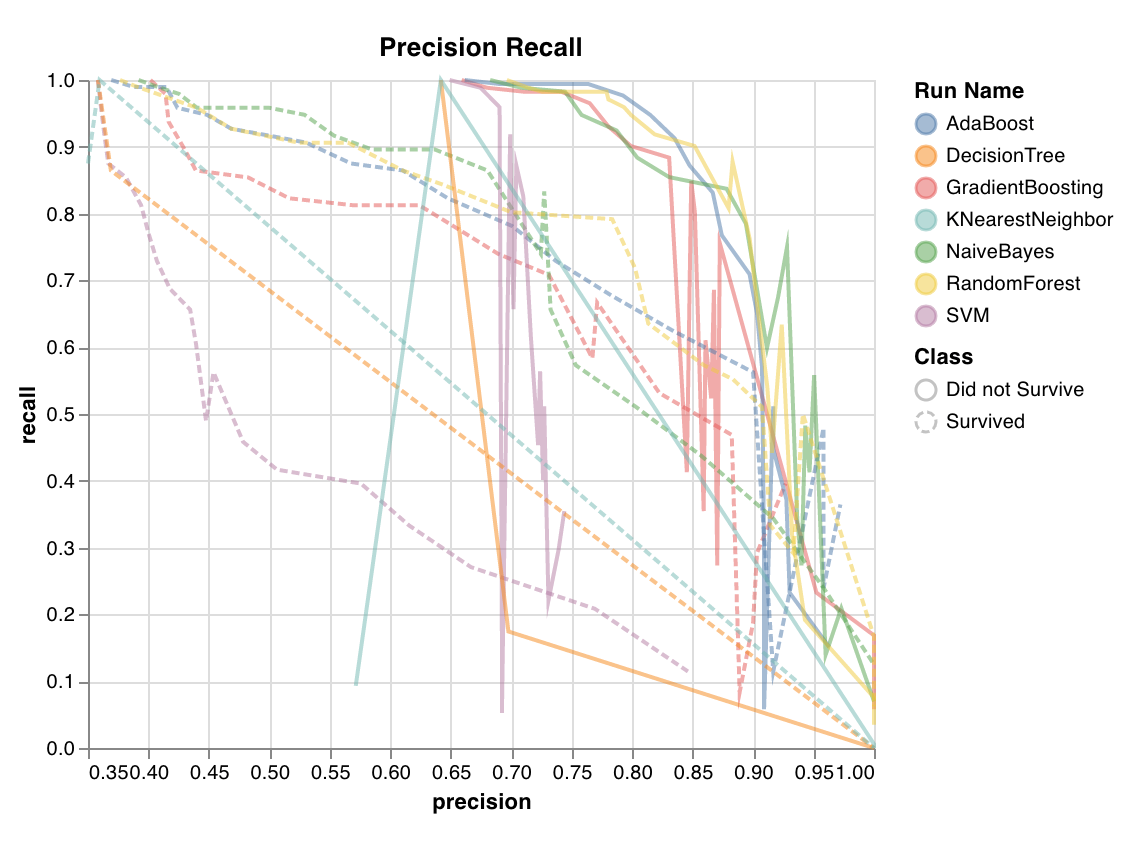
wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)
- y_true (arr): Test set labels.
- y_probas (arr): Test set predicted probabilities.
- labels (list): Named labels for target variable (y).
Feature importances
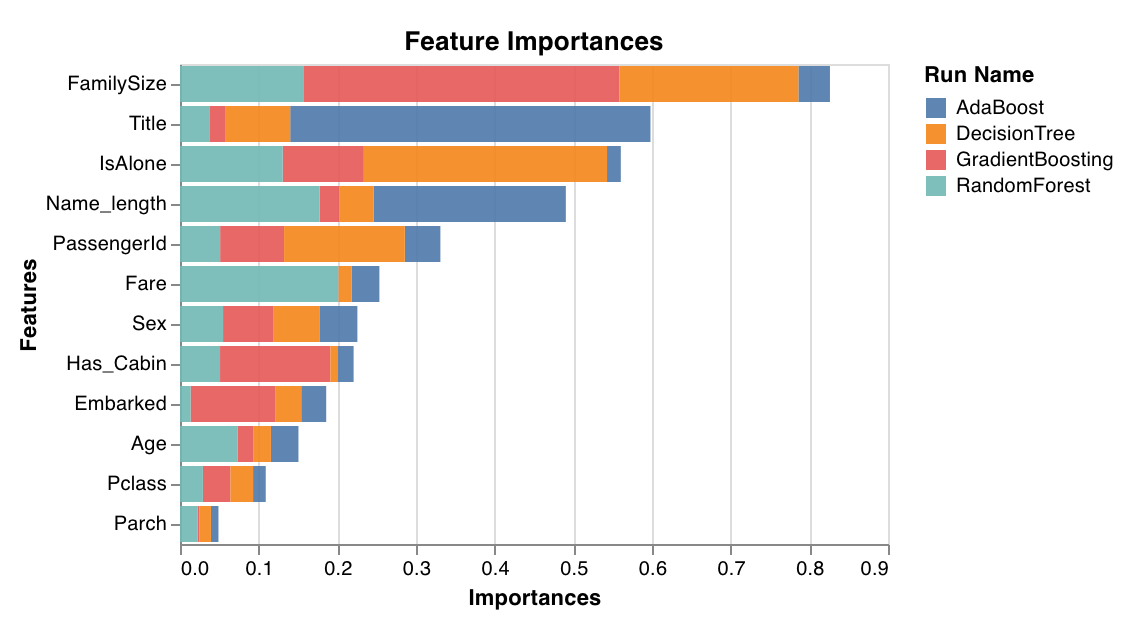
feature_importances_ attribute, like trees.
wandb.sklearn.plot_feature_importances(model, ['width', 'height, 'length'])
- model (clf): Takes in a fitted classifier.
- feature_names (list): Names for features. Makes plots easier to read by replacing feature indexes with corresponding names.
Calibration curve
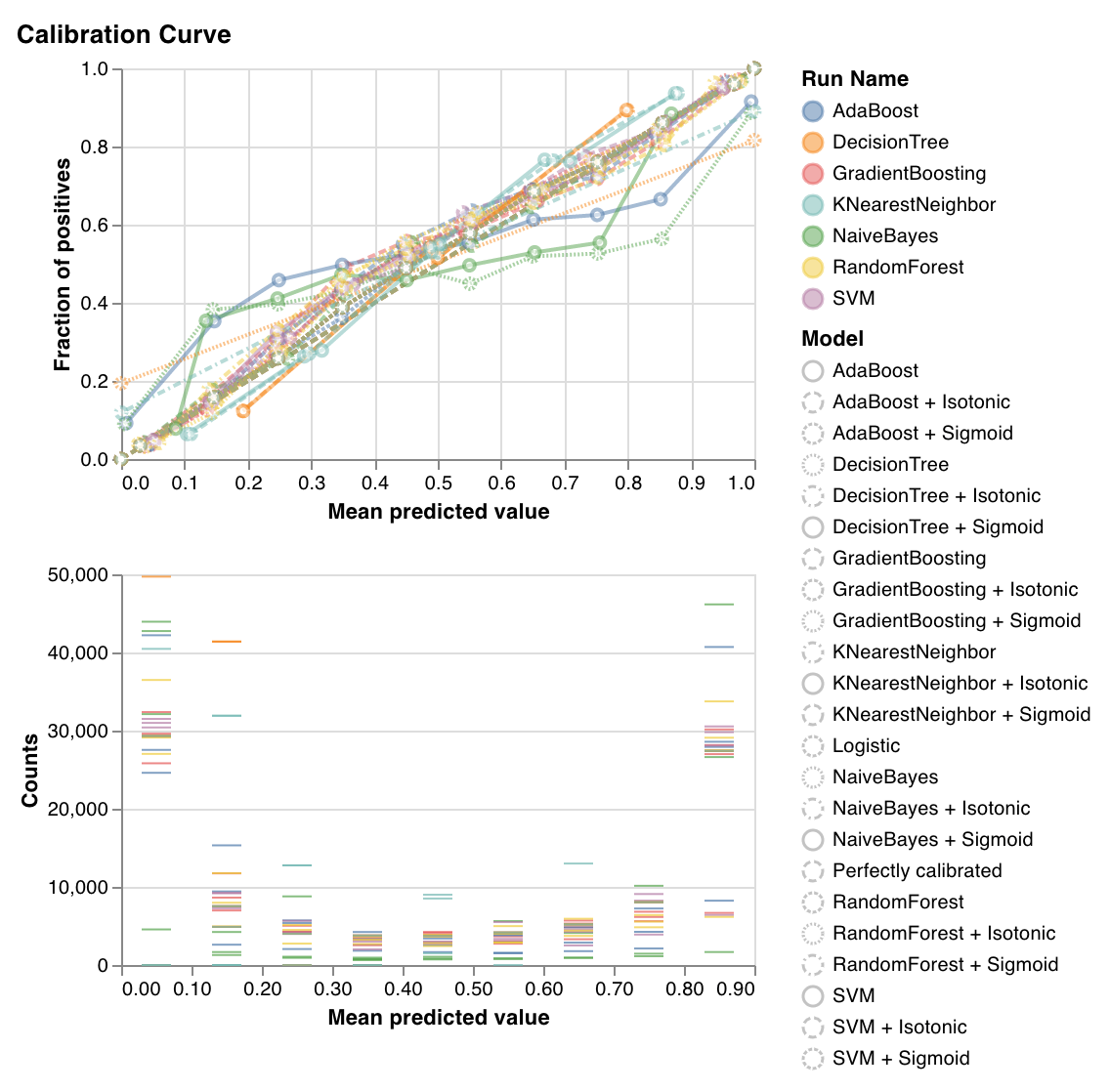
wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')
- model (clf): Takes in a fitted classifier.
- X (arr): Training set features.
- y (arr): Training set labels.
- model_name (str): Model name. Defaults to ‘Classifier’
Confusion matrix
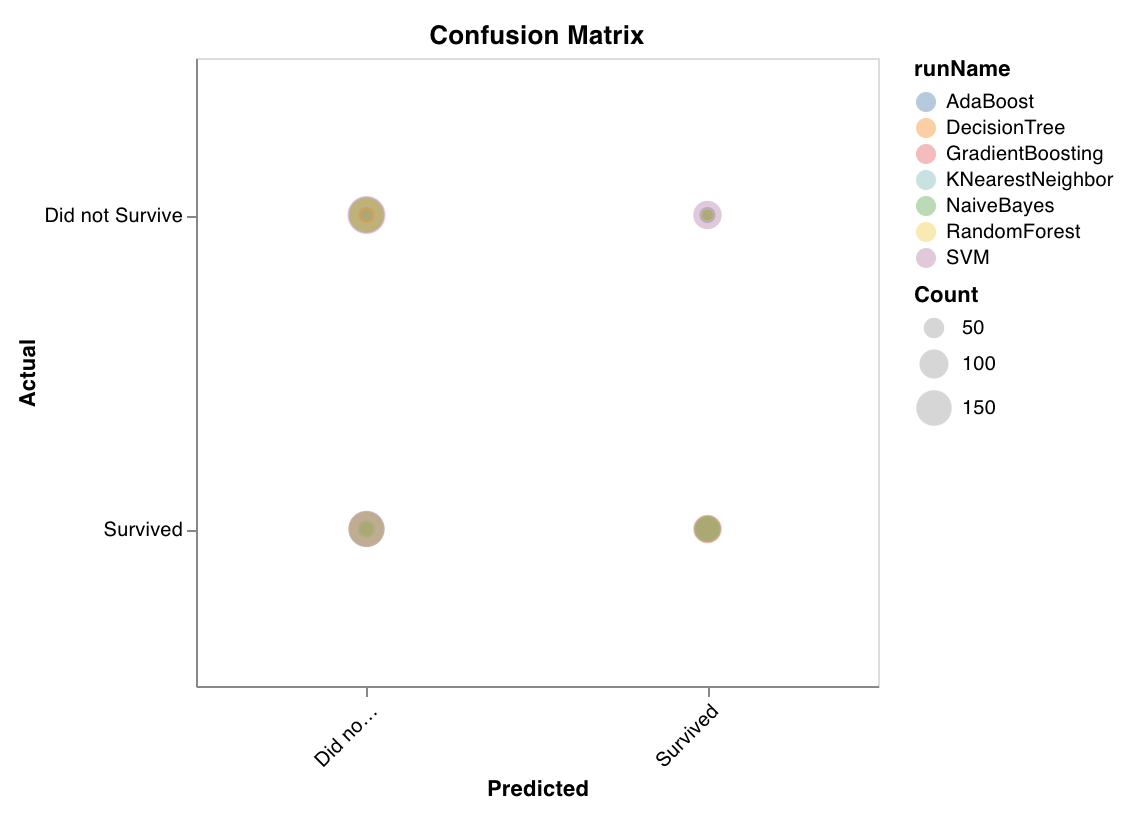
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
- y_true (arr): Test set labels.
- y_pred (arr): Test set predicted labels.
- labels (list): Named labels for target variable (y).
Summary metrics
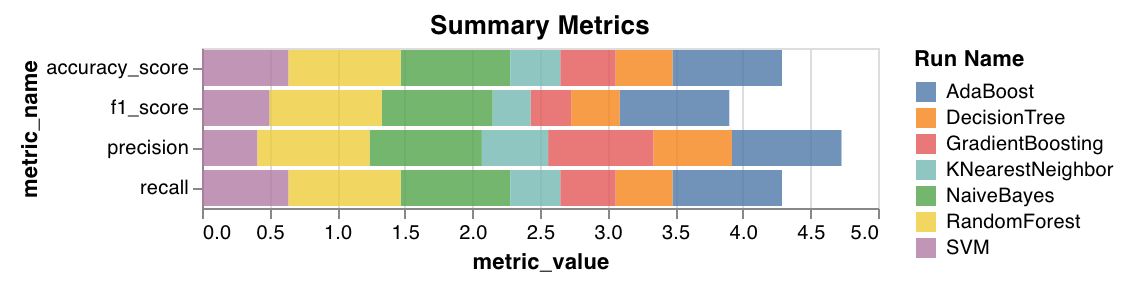
- Calculates summary metrics for classification, such as
mse,mae, andr2score. - Calculates summary metrics for regression, such as
f1, accuracy, precision, and recall.
wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)
- model (clf or reg): Takes in a fitted regressor or classifier.
- X (arr): Training set features.
- y (arr): Training set labels.
- X_test (arr): Test set features.
- y_test (arr): Test set labels.
Elbow plot
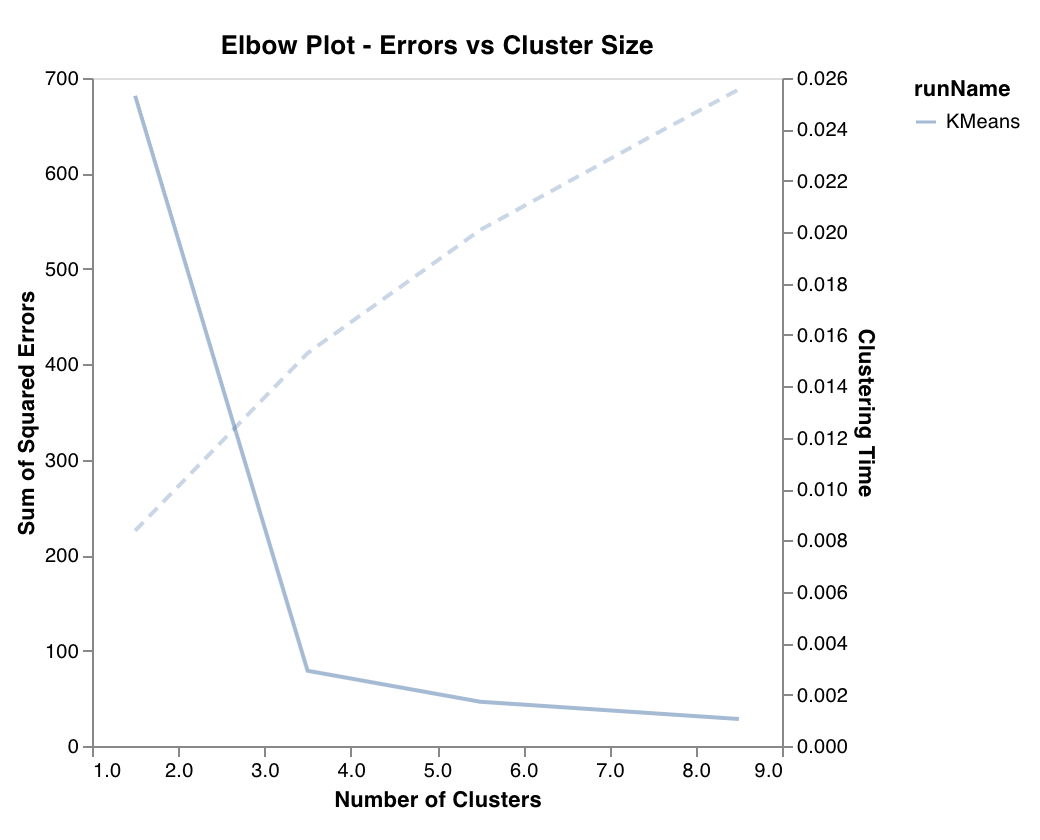
wandb.sklearn.plot_elbow_curve(model, X_train)
- model (clusterer): Takes in a fitted clusterer.
- X (arr): Training set features.
Silhouette plot
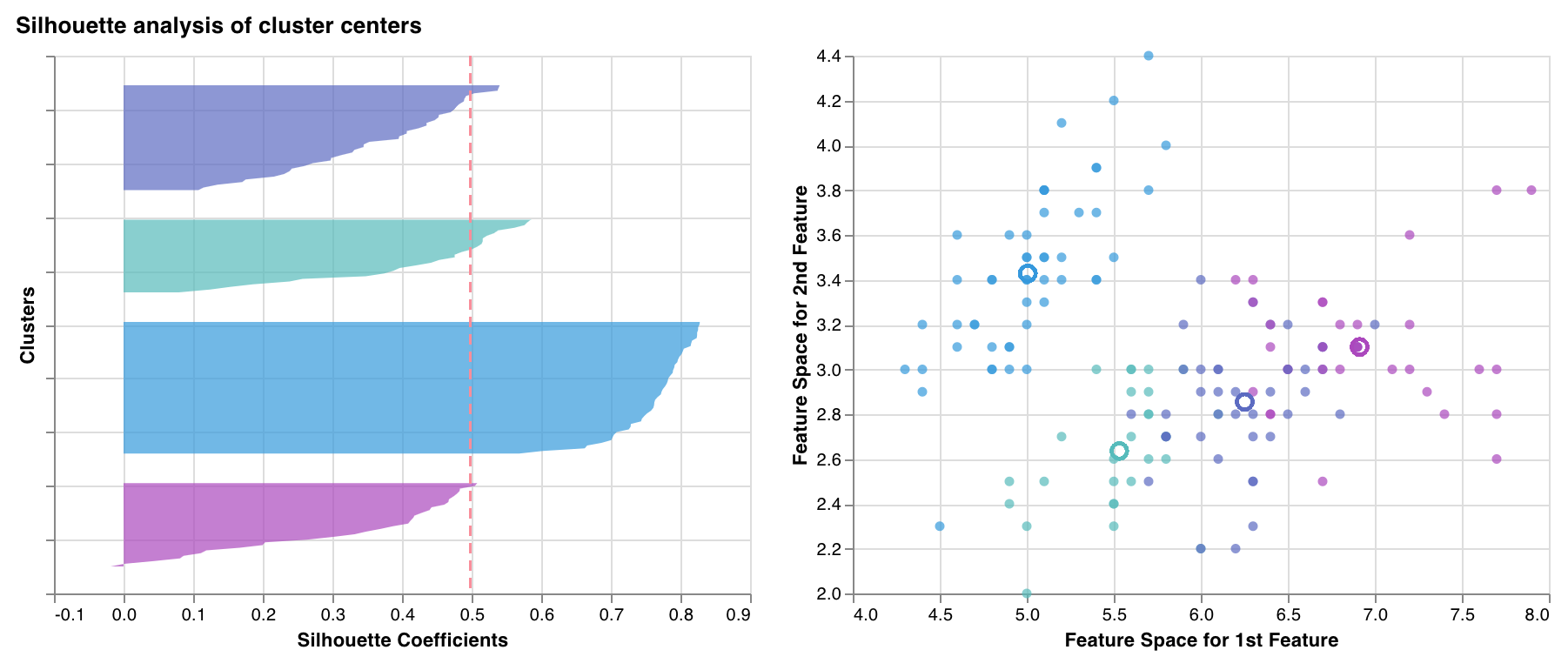
wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])
- model (clusterer): Takes in a fitted clusterer.
- X (arr): Training set features.
- cluster_labels (list): Names for cluster labels. Makes plots easier to read by replacing cluster indexes with corresponding names.
Outlier candidates plot
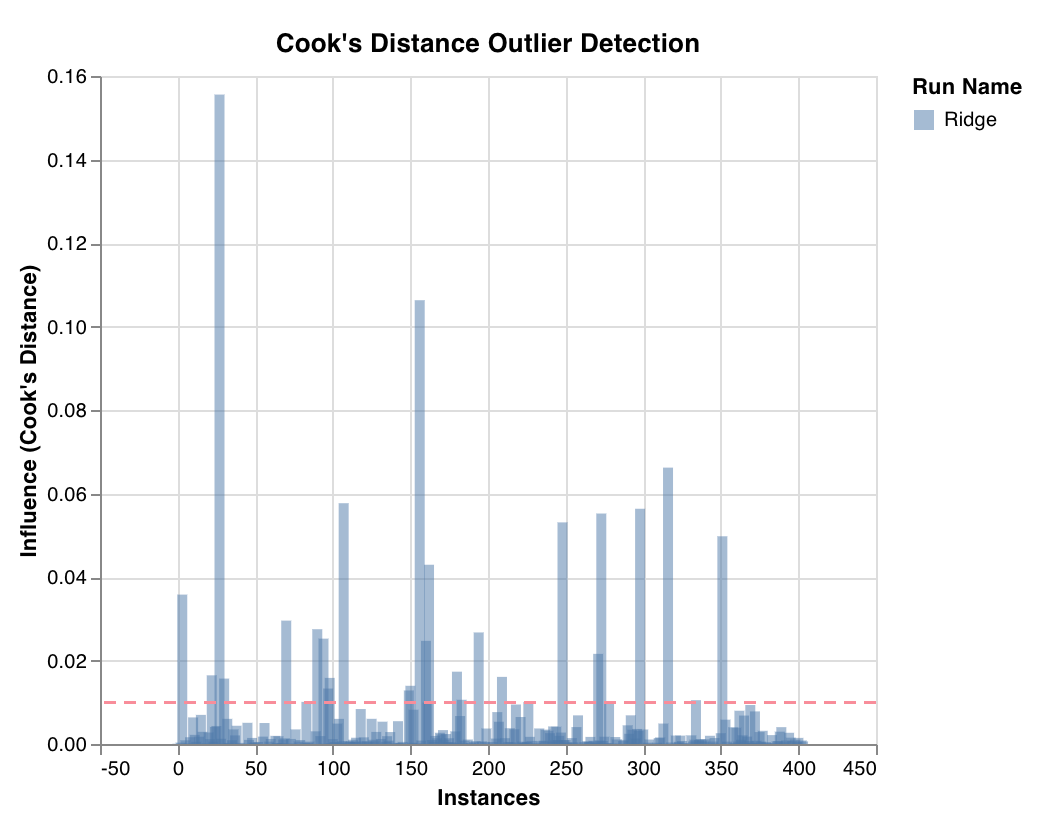
wandb.sklearn.plot_outlier_candidates(model, X, y)
- model (regressor): Takes in a fitted classifier.
- X (arr): Training set features.
- y (arr): Training set labels.
Residuals plot
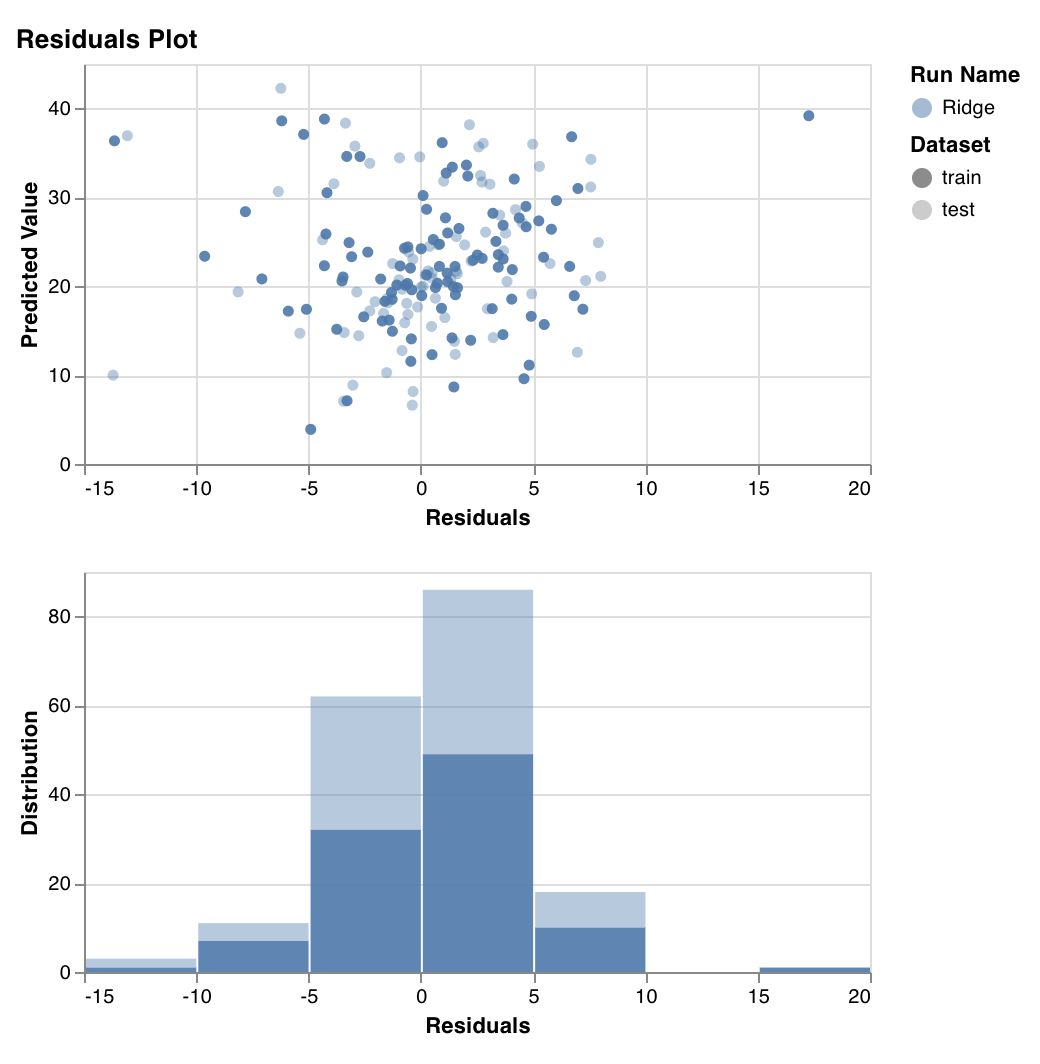
wandb.sklearn.plot_residuals(model, X, y)
- model (regressor): Takes in a fitted classifier.
- X (arr): Training set features.
- y (arr): Training set labels. If you have any questions, we’d love to answer them in our slack community.
Example
- Run in colab: A simple notebook to get you started.