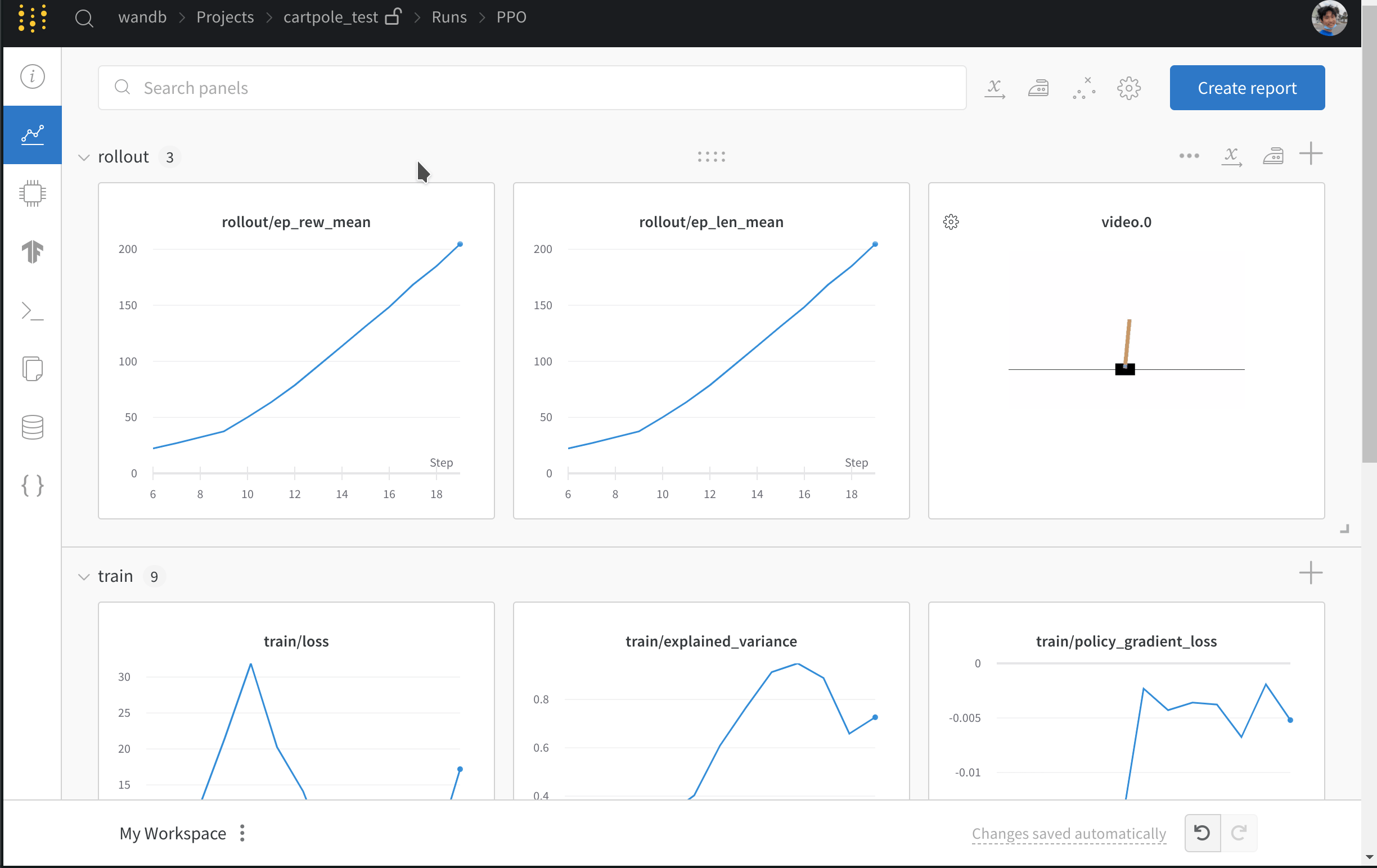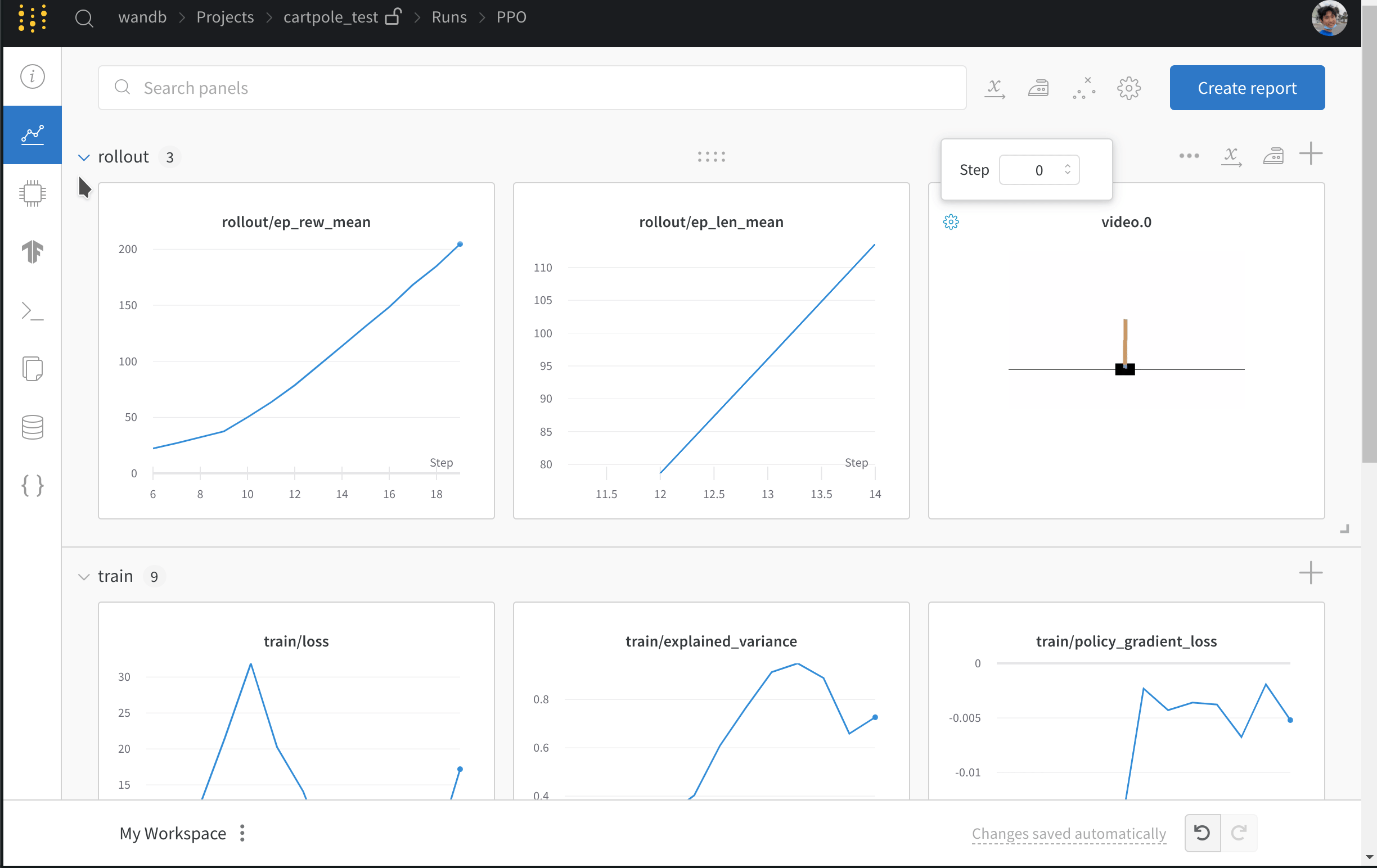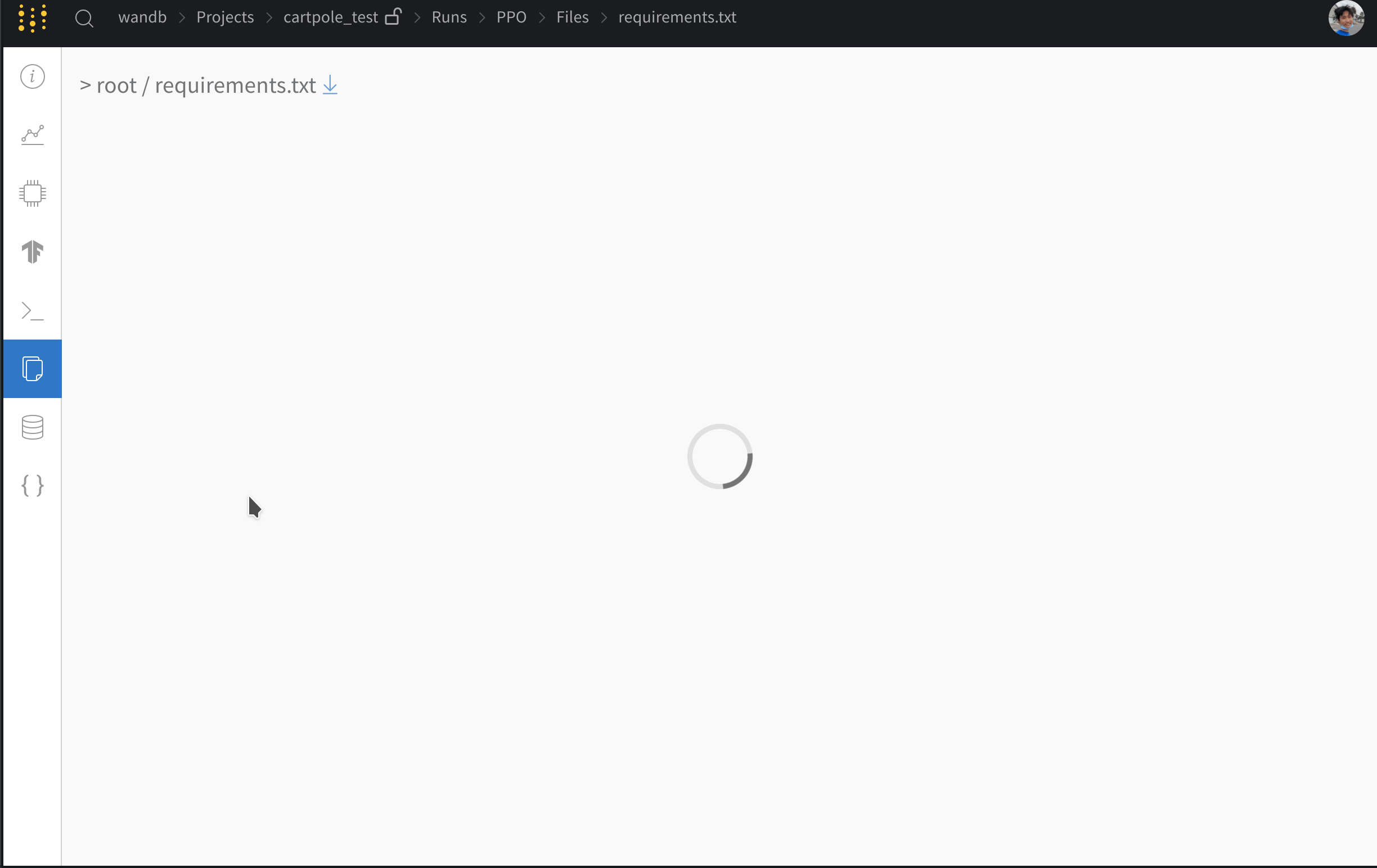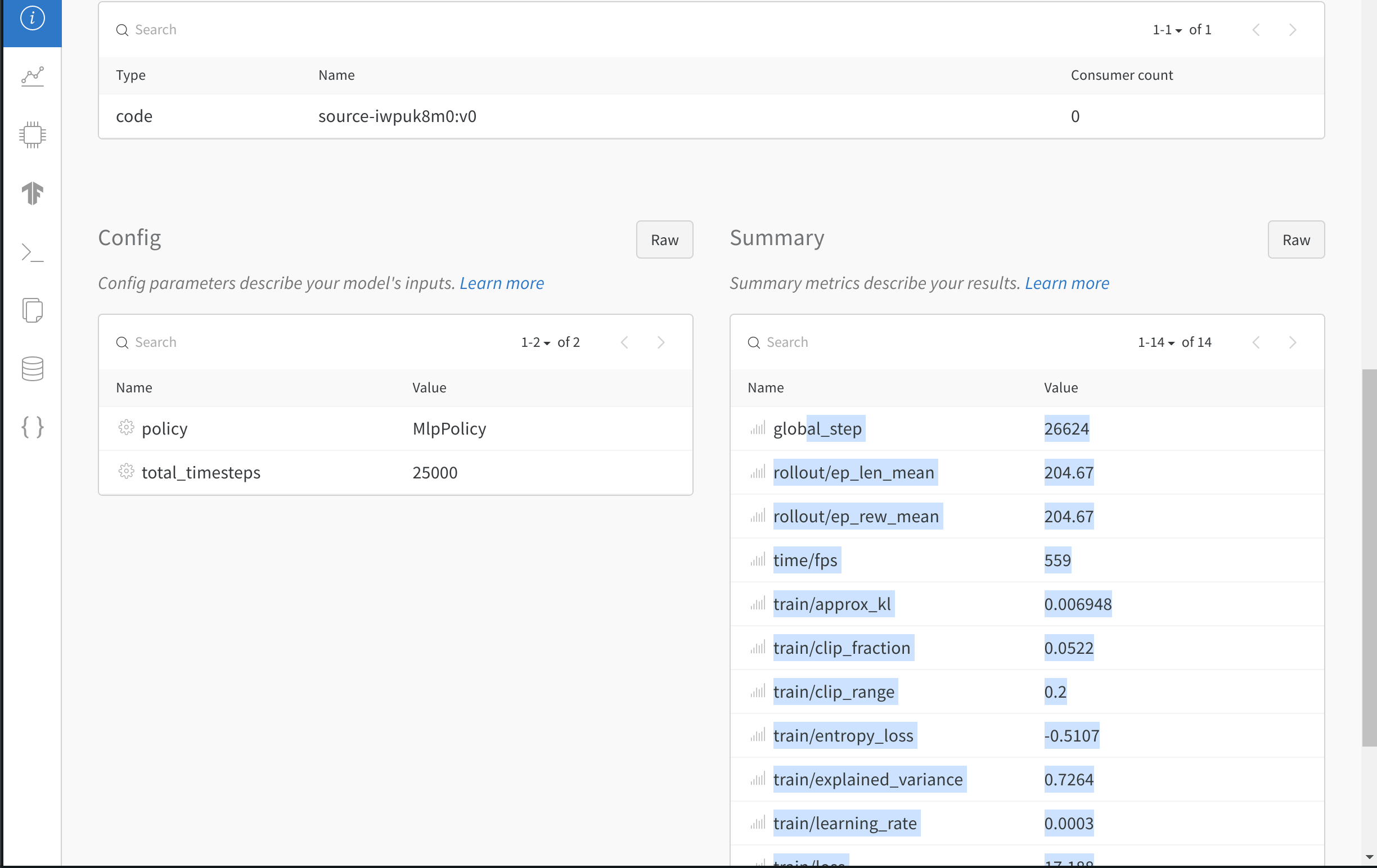
- Records metrics such as losses and episodic returns.
- Uploads videos of agents playing the games.
- Saves the trained model.
- Logs the model’s hyperparameters.
- Logs the model gradient histograms.
Log your SB3 experiments
WandbCallback Arguments
| Argument | Usage |
|---|---|
verbose | The verbosity of sb3 output |
model_save_path | Path to the folder where the model will be saved, The default value is `None` so the model is not logged |
model_save_freq | Frequency to save the model |
gradient_save_freq | Frequency to log gradient. The default value is 0 so the gradients are not logged |