Get started
To integrate Verifiers with Weave, start by installing the Verifiers library usinguv (recommended by the library’s authors). Use one of the following commands to install the library:
Trace rollouts and evaluate
Once you’ve installed the necessary libraries, you can use Weave and Verifiers together to trace calls and run evaluations. The following example script demonstrates how to run an evaluation with Verifiers and log the results to Weave. The script tests the LLM’s ability to solve math problems using the GSM8K dataset. It asks GPT-4 to solve two math problems, extracts the numerical value from each response, and then grades the attempt using Verifiers as an evaluation framework. Run the example and inspect the results in Weave:Fine-tune a model with experiment tracking and tracing
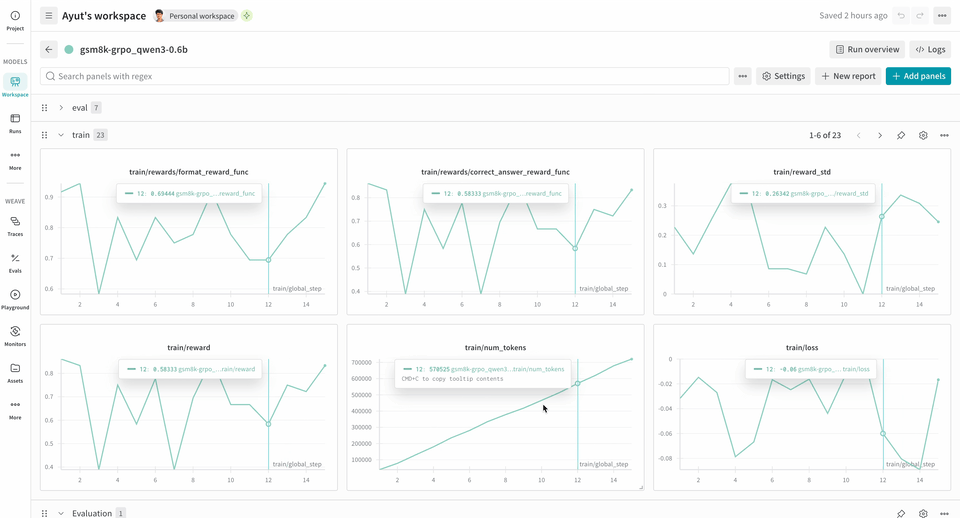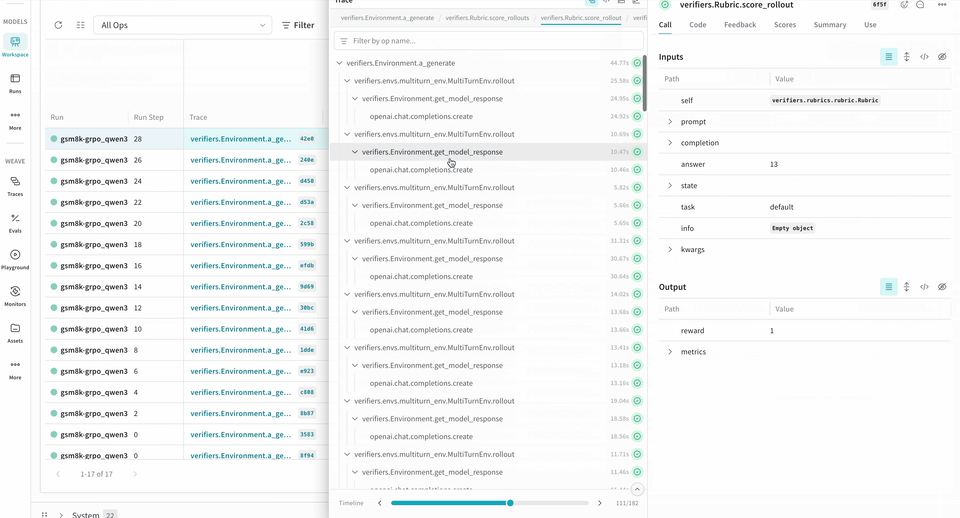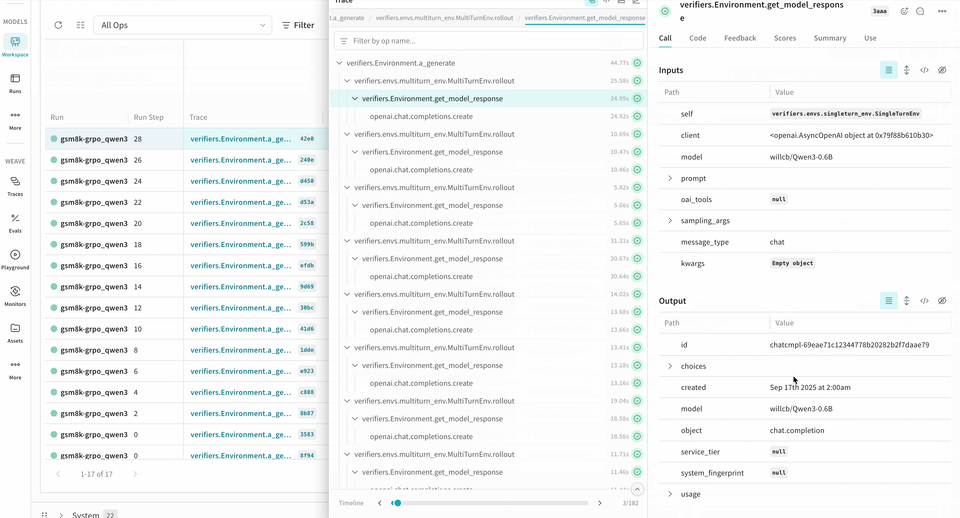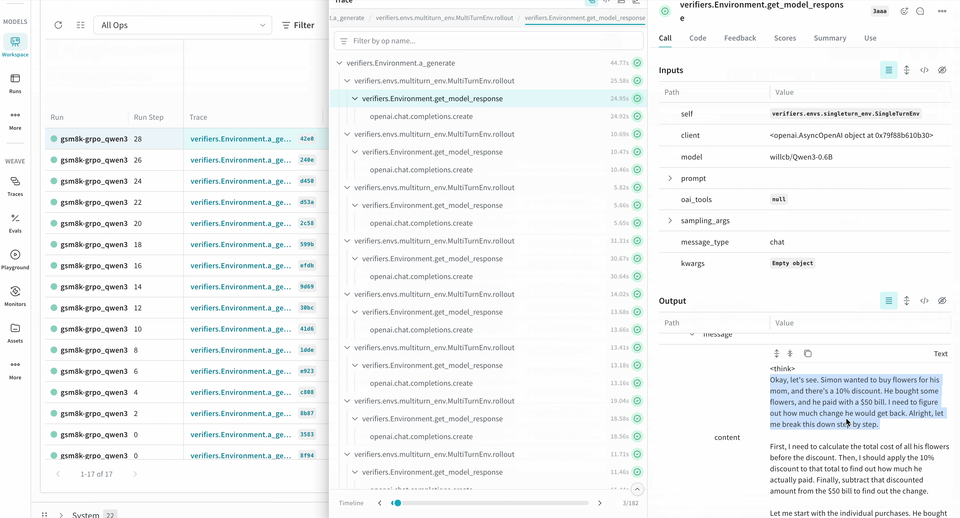
Weave provides insight into how your models perform during RL fine-tuning. When you use it alongside W&B, you get observability across the workflow. W&B tracks training metrics and performance charts, while Weave captures detailed traces of each interaction during the training process. Theverifiers repository includes ready-to-run examples to help you get started.
The following example RL training pipeline runs a local inference server and trains a model using the GSM8K dataset. The model responds with answers to the math problems and the training loop scores the output and updates the model accordingly. W&B logs the training metrics, like loss, reward, and accuracy, while Weave captures the input, output, reasoning, and scoring.
To use this pipeline:
- Install the framework from the source. The following commands install the Verifiers library from GitHub and the necessary dependencies:
- Install an off-the-shelf environment. The following command installs the pre-configured GSM8K training environment:
- Train your model. The following commands launch the inference server and training loop, respectively. This example workflow sets
report_to=wandbby default, so you don’t need to callwandb.init()separately. You’ll be prompted to authenticate this machine to log metrics to W&B.
This example was tested on 2xH100s with the following environment variables set for increased stability:These variables disable CUDA Unified Memory (CuMem) for device memory allocations.
logprobs for the Environment.a_generate and Rubric.score_rollouts methods. This keeps payloads small while leaving the originals intact for training.