Documentation Index
Fetch the complete documentation index at: https://docs.wandb.ai/llms.txt
Use this file to discover all available pages before exploring further.
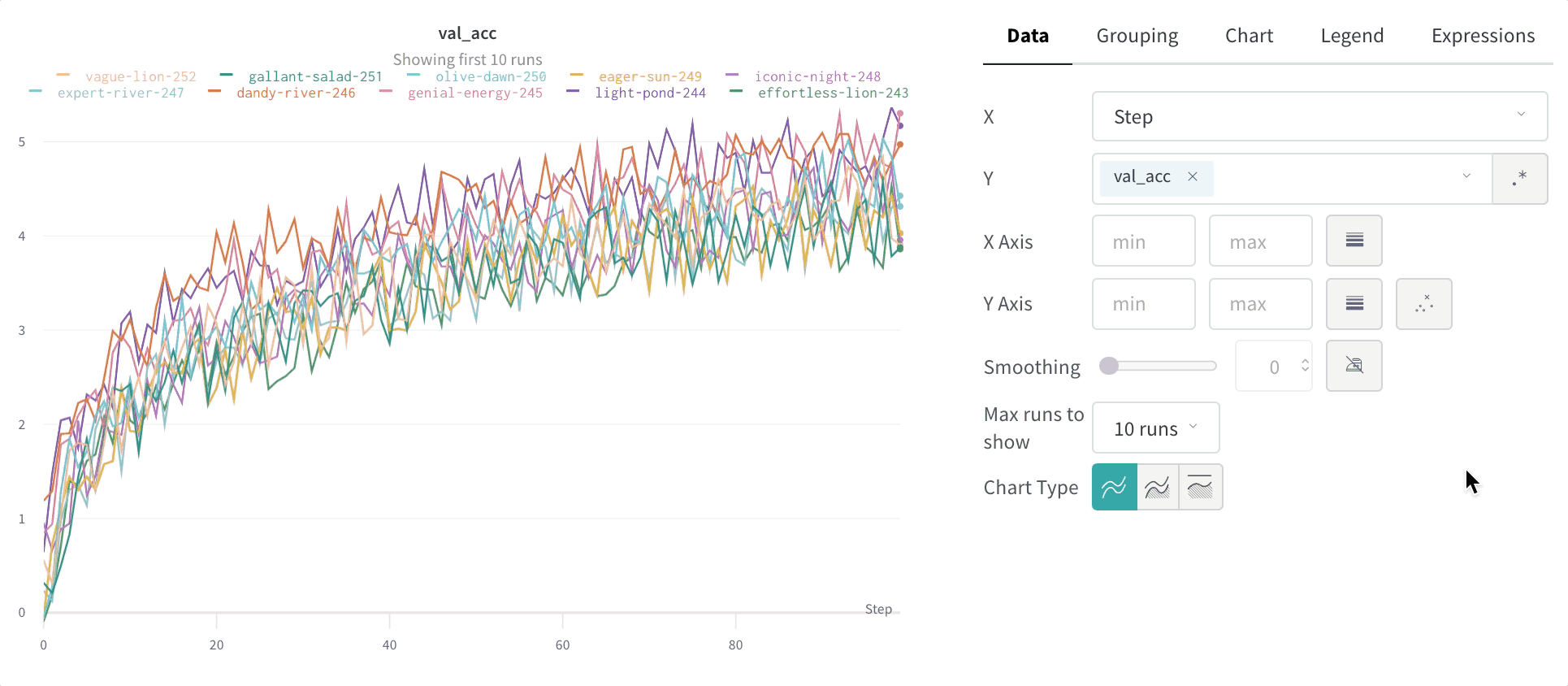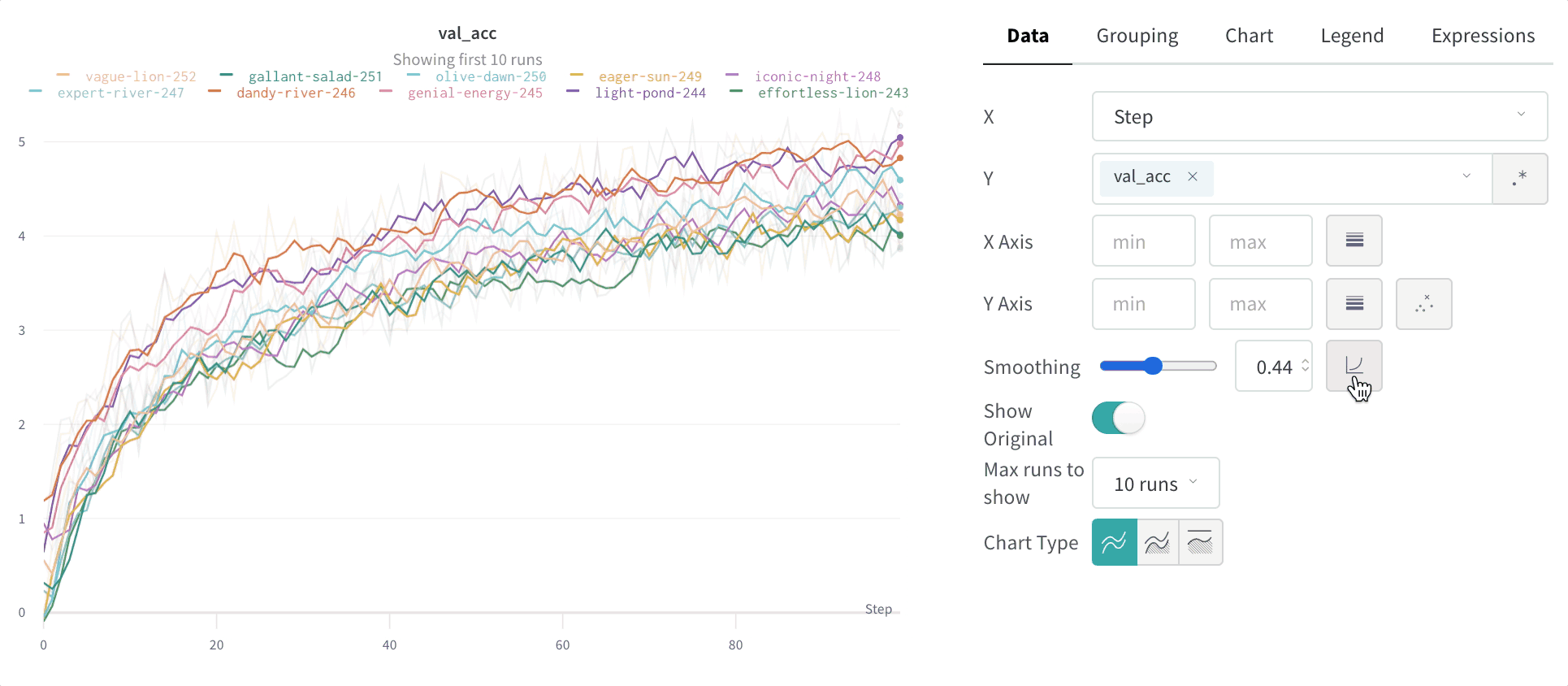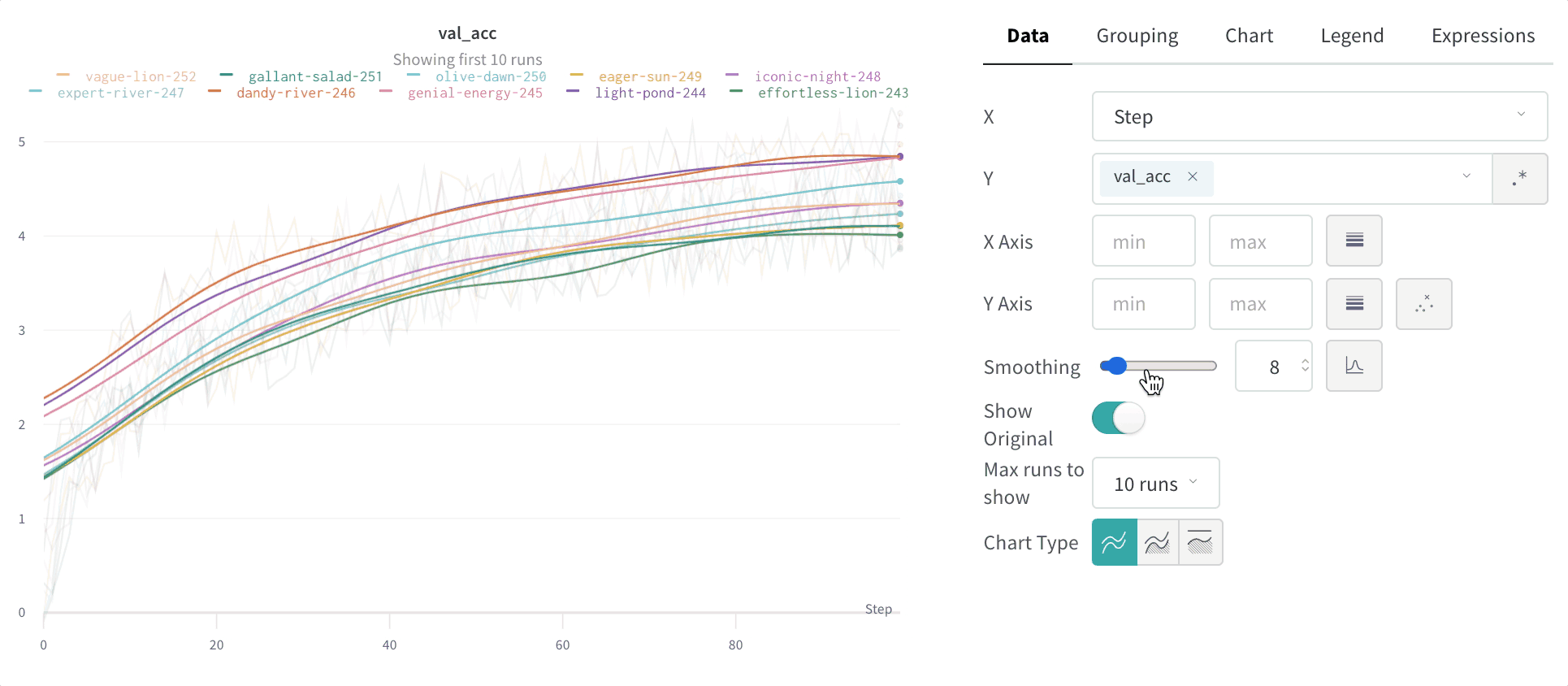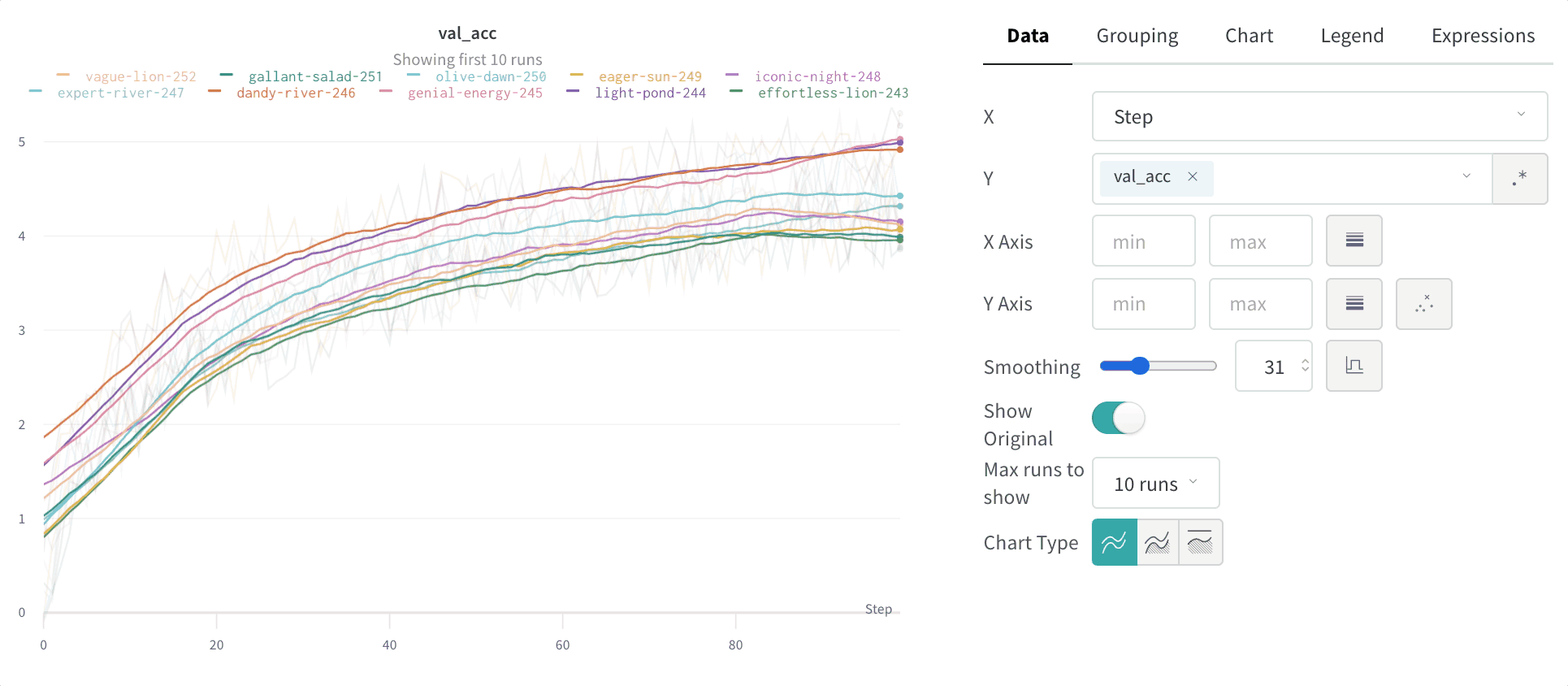
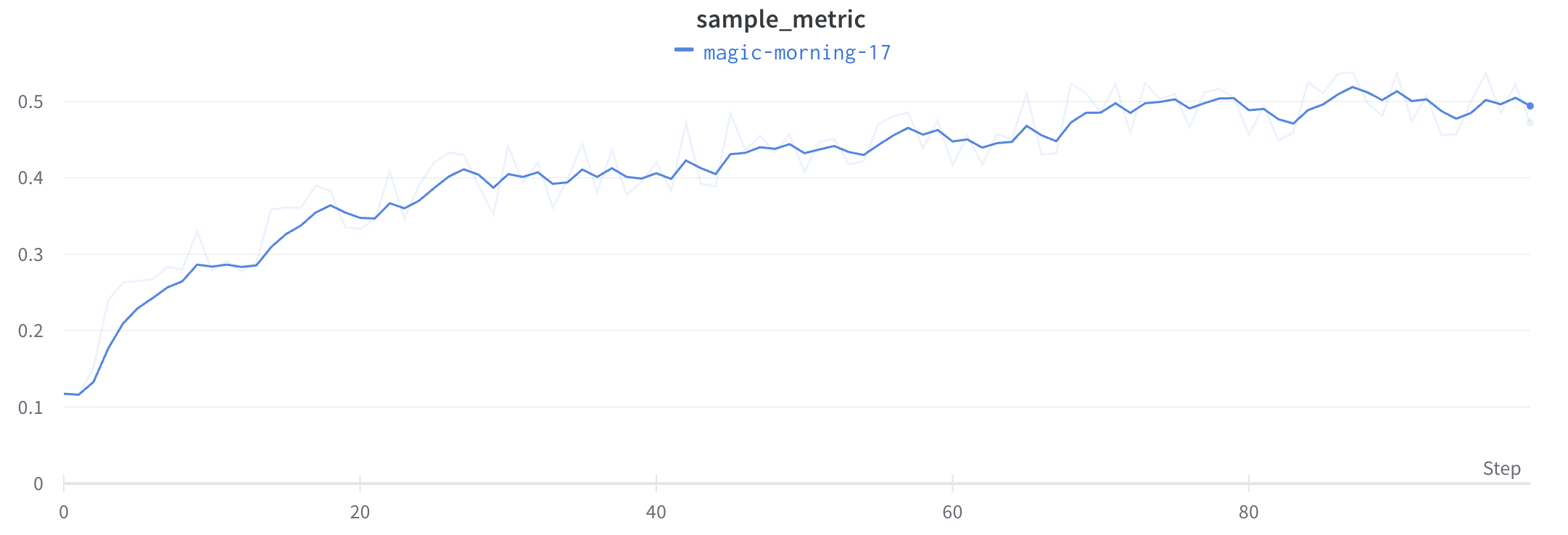
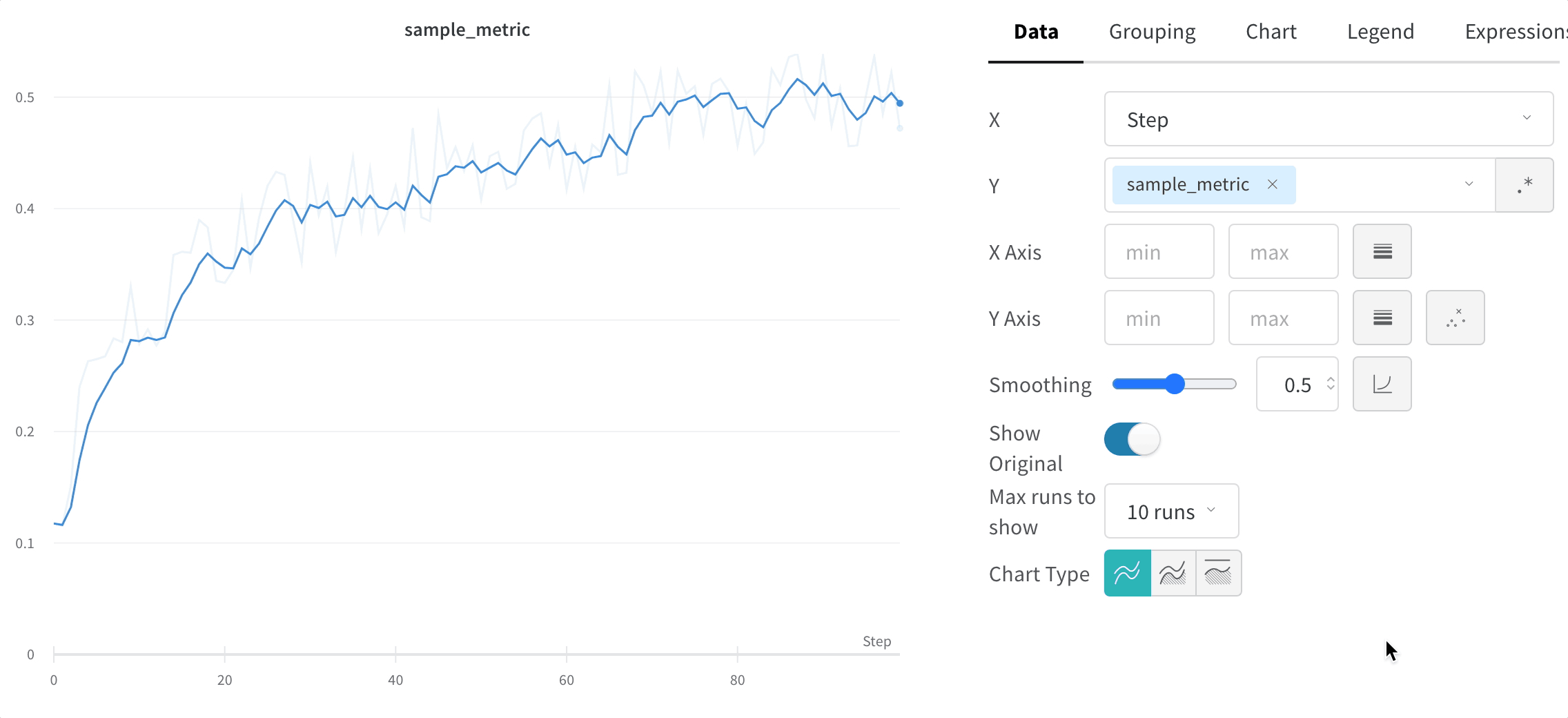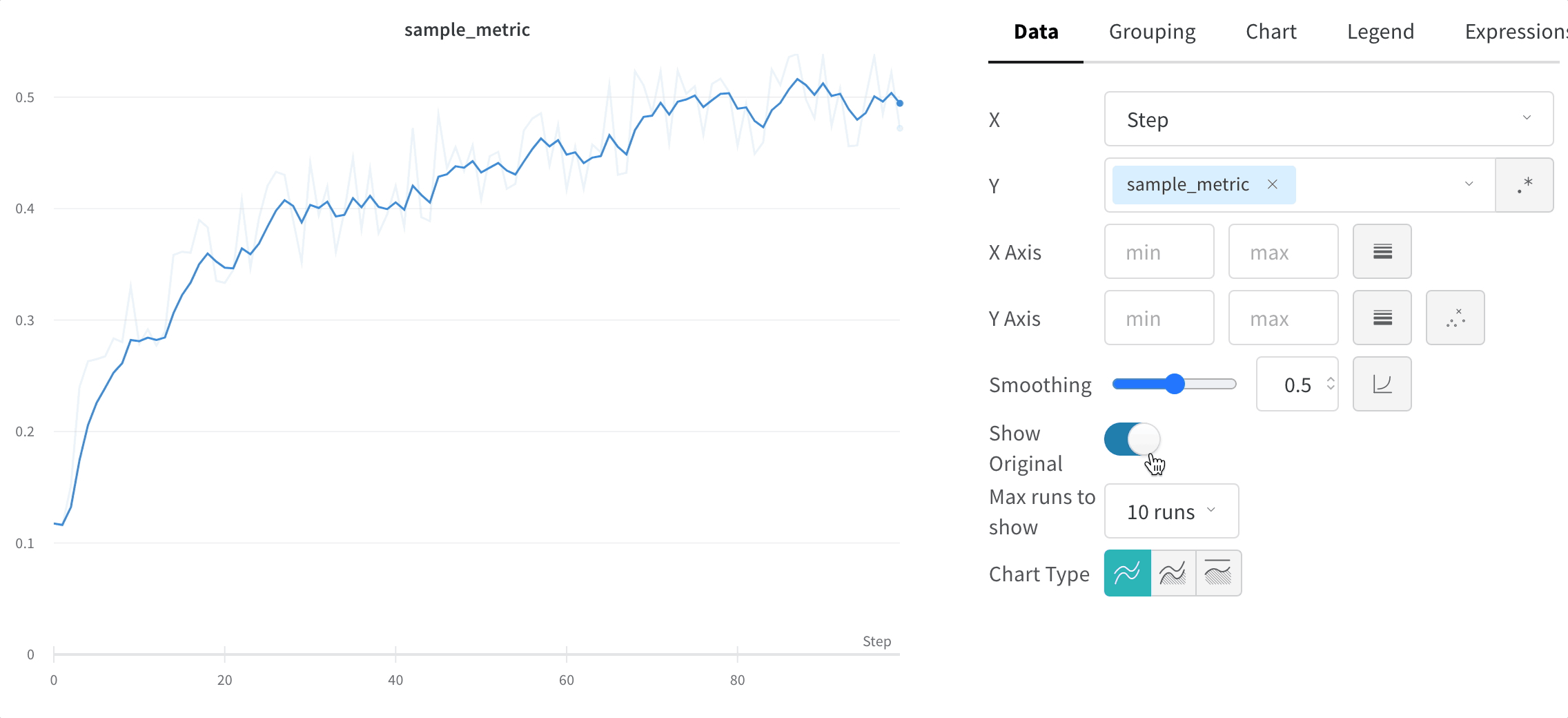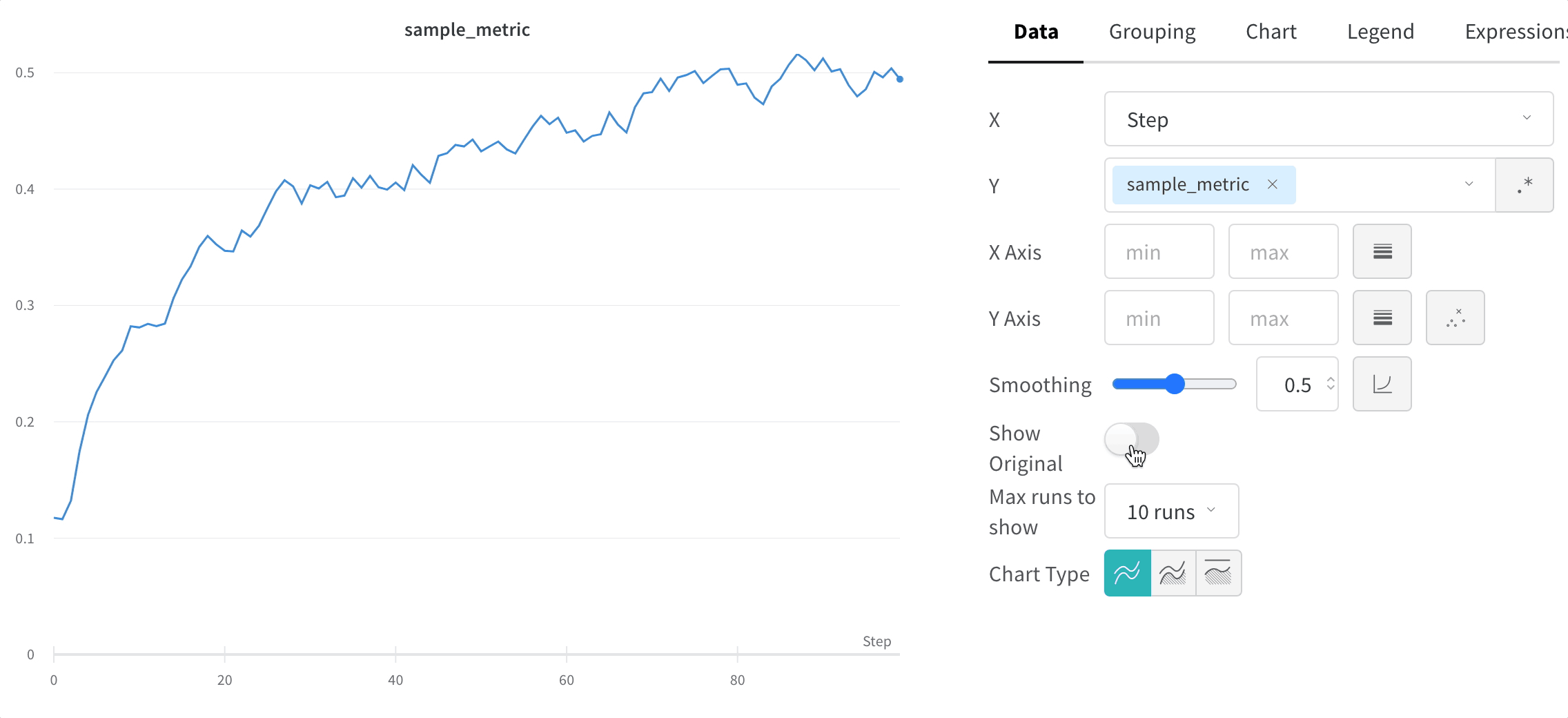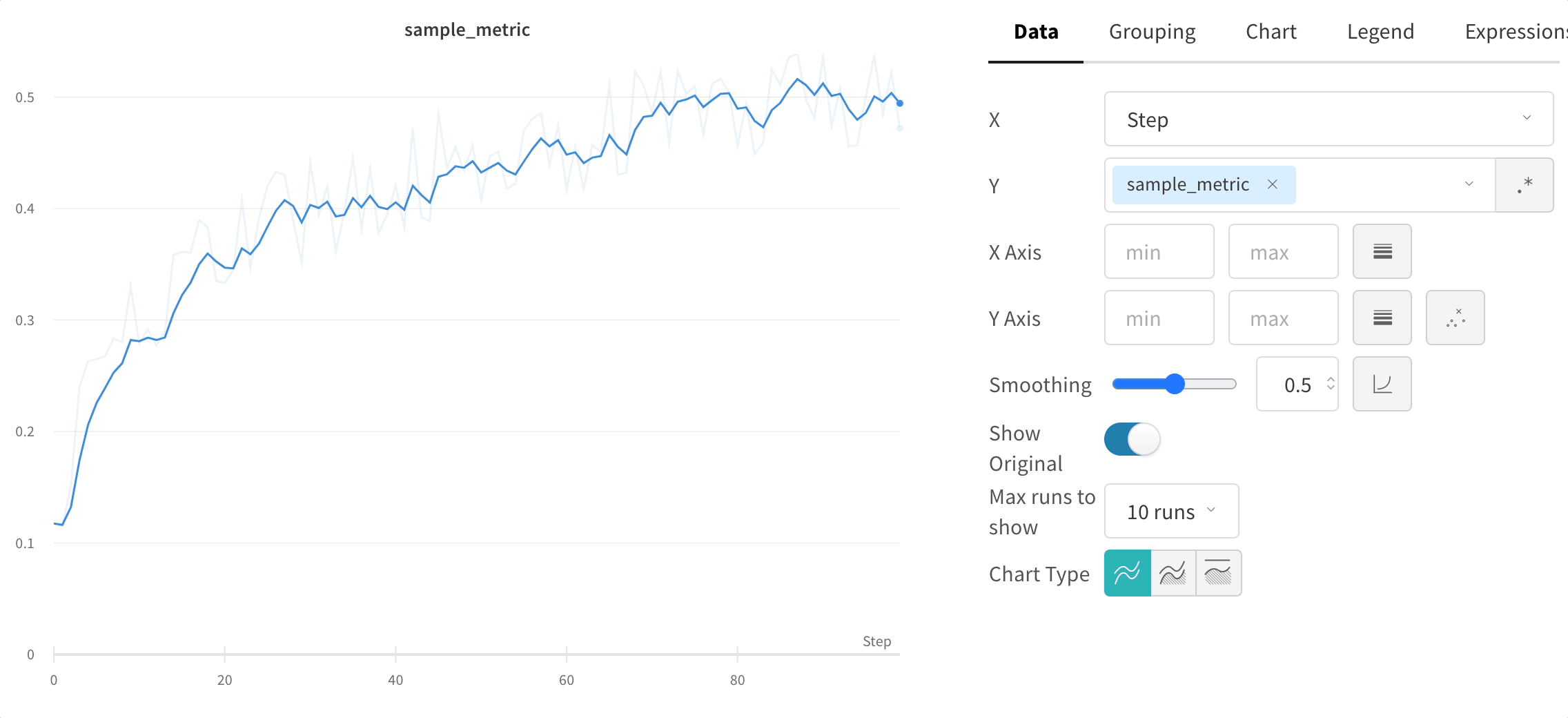
스무딩은 점 간 변동을 줄여 노이즈가 많은 선형 플롯에서 추세를 파악하는 데 도움을 주며, 그 결과 기본 신호를 더 쉽게 읽을 수 있게 합니다. 이 페이지에서는 W&B가 지원하는 스무딩 알고리즘, 각각이 가장 유용한 경우, 그리고 원본 데이터를 계속 표시할지 여부를 제어하는 방법을 설명합니다.
W&B는 여러 유형의 스무딩을 지원합니다:
이 알고리즘들이 실제 데이터에 적용된 모습을 보려면 다음 대화형 W&B 리포트를 확인해 보세요.
시간 가중 지수 이동 평균(TWEMA) 스무딩(기본값)
y 값의 개수)를 고려합니다. 이를 통해 특성이 서로 다른 여러 라인을 동시에 표시할 때도 일관된 스무딩을 적용할 수 있습니다.
다음 샘플 코드는 이 동작이 내부적으로 어떻게 작동하는지 보여줍니다:
const smoothingWeight = Math.min(Math.sqrt(smoothingParam || 0), 0.999);
let lastY = yValues.length > 0 ? 0 : NaN;
let debiasWeight = 0;
return yValues.map((yPoint, index) => {
const prevX = index > 0 ? index - 1 : 0;
// VIEWPORT_SCALE는 결과를 차트의 x축 범위에 맞게 조정합니다
const changeInX =
((xValues[index] - xValues[prevX]) / rangeOfX) * VIEWPORT_SCALE;
const smoothingWeightAdj = Math.pow(smoothingWeight, changeInX);
lastY = lastY * smoothingWeightAdj + yPoint;
debiasWeight = debiasWeight * smoothingWeightAdj + 1;
return lastY / debiasWeight;
});
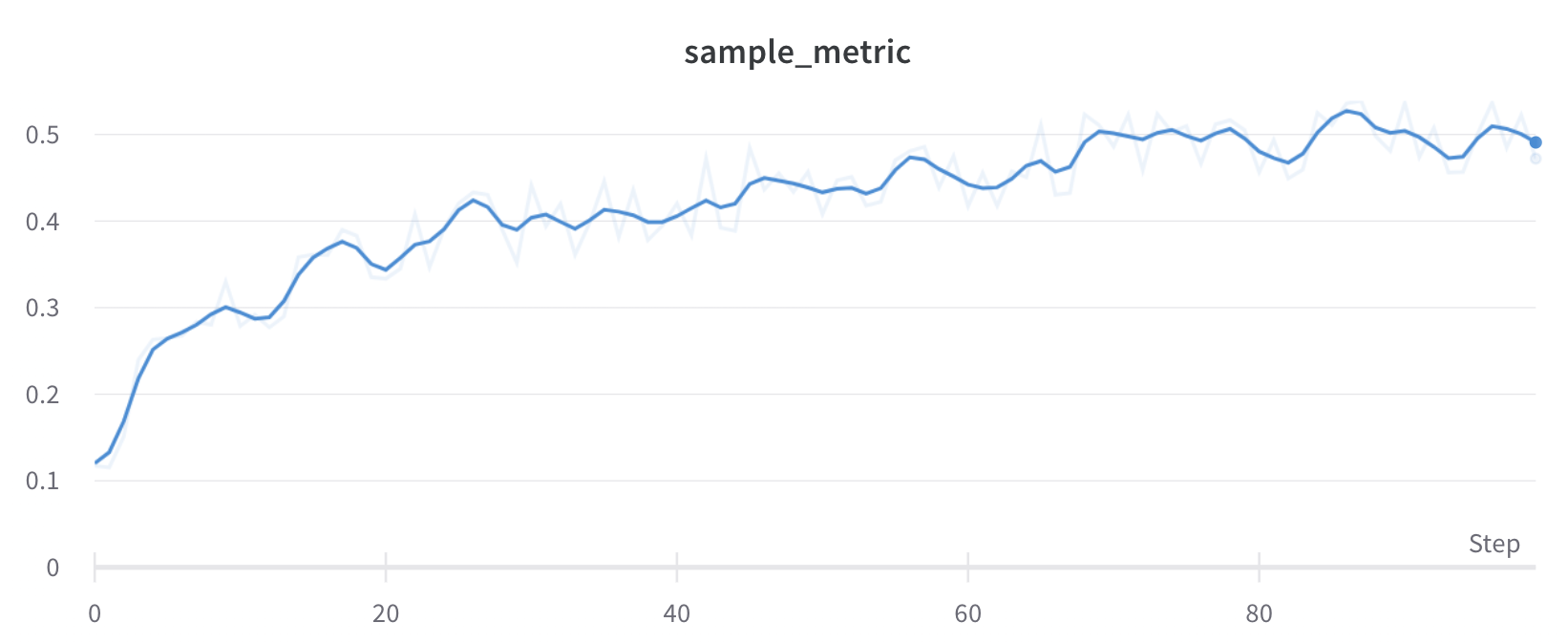
x 값마다 스무딩된 값을 계산하며, 해당 값의 앞뒤에 있는 점들을 모두 반영합니다.
이 알고리즘이 라이브 데이터에 적용되는 방식을 보려면 대화형 W&B 리포트의 가우시안 스무딩 섹션을 참조하세요.
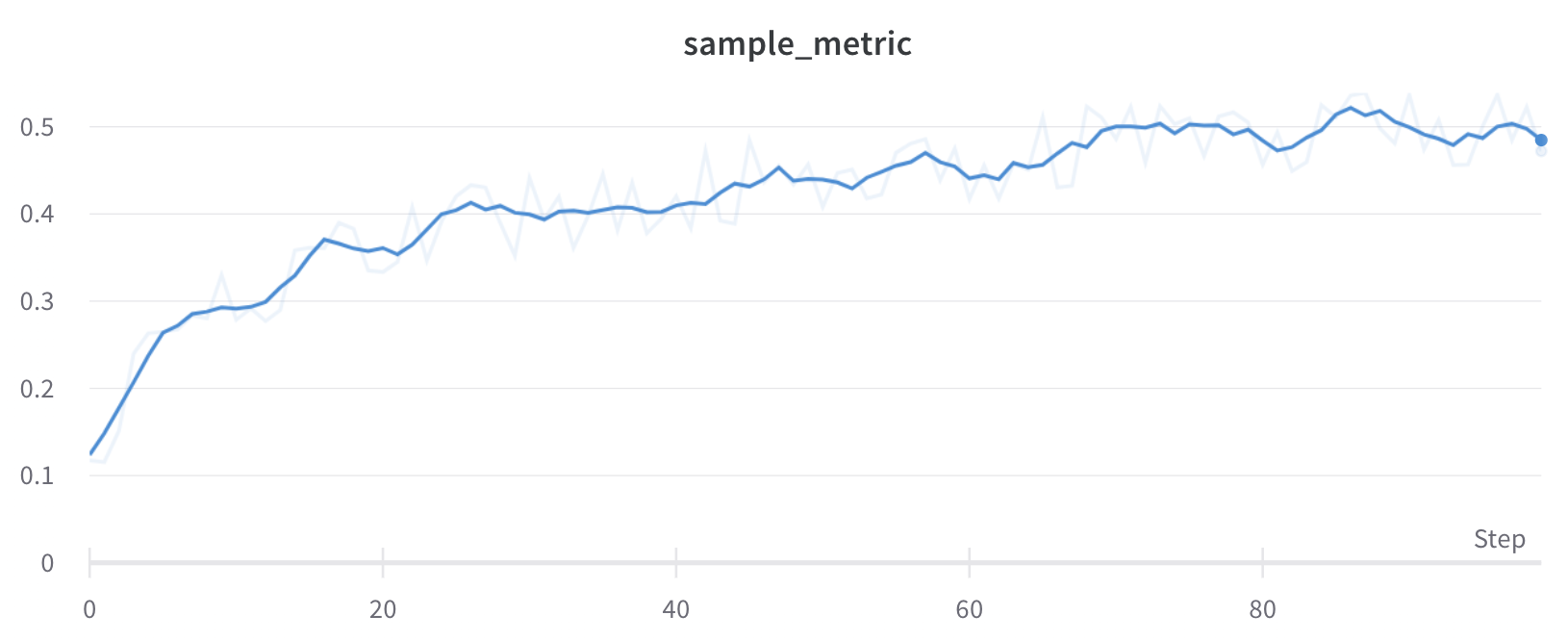
이동 평균은 주어진 x 값 전후의 윈도우에 있는 점들의 평균으로 해당 점을 대체하는 스무딩 알고리즘입니다. “Boxcar Filter” on Wikipedia를 참조하세요. 이동 평균에 대해 선택한 파라미터는 이동 평균에 포함할 점의 개수를 지정합니다.
점들이 x축에 고르지 않게 분포되어 있다면 대신 가우시안 스무딩을 사용하세요. 점 밀도가 달라질 때는 고정 폭 윈도우가 오해의 소지가 있는 평균을 만들 수 있기 때문입니다.
이 알고리즘이 라이브 데이터에 적용된 모습을 보려면 대화형 W&B 리포트의 이동 평균 section을 참조하세요.
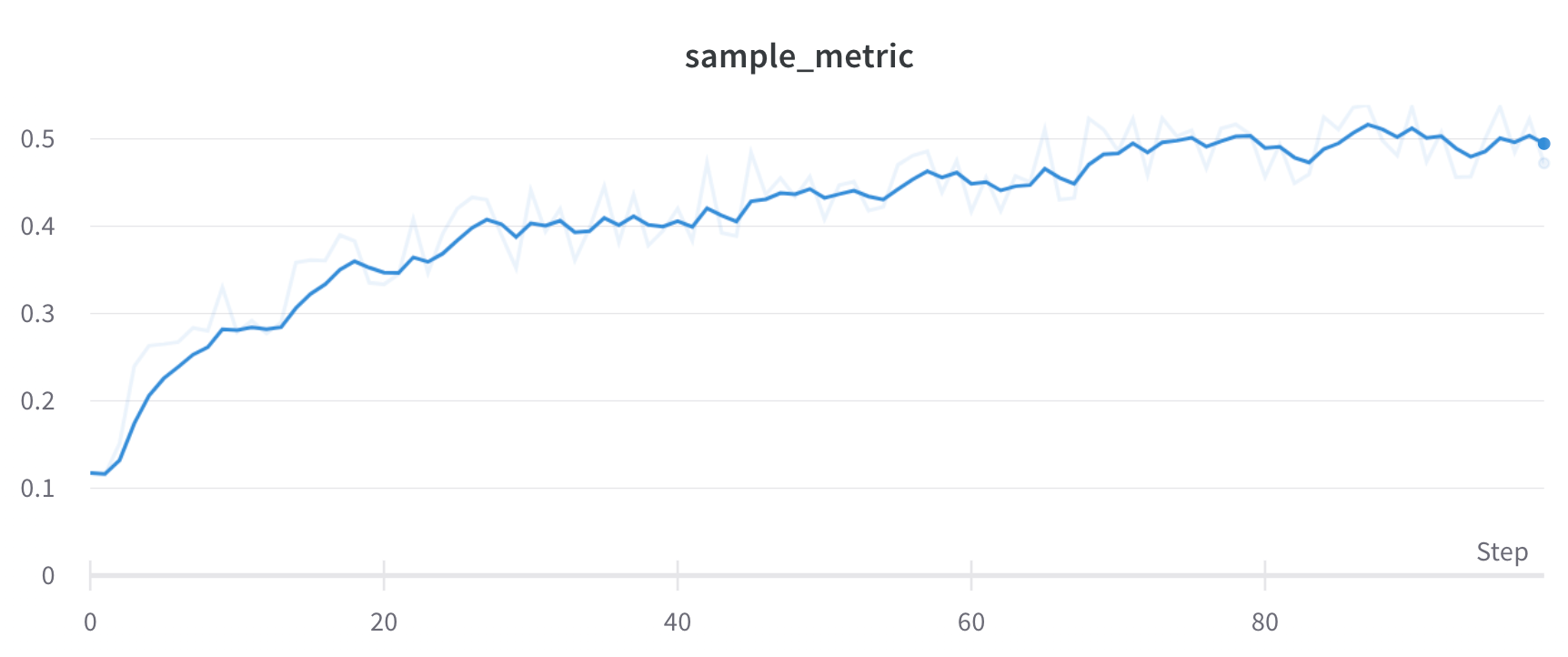
지수 이동 평균(EMA) 스무딩 알고리즘은 지수 윈도 함수로 시계열 데이터를 스무딩하는 데 사용하는 휴리스틱 기법입니다. 이 기법에 대한 자세한 내용은 Exponential Smoothing을 참조하세요. 범위는 0~1입니다. 시계열의 초기 값이 0으로 편향되지 않도록 디바이어스 항이 추가됩니다.
대부분의 경우 EMA 스무딩는 먼저 버킷팅한 다음 스무딩하는 대신, 이력 전체를 스캔한 뒤 적용됩니다. 이렇게 하면 더 정확하게 스무딩되는 경우가 많습니다.
다음과 같은 경우에는 대신 EMA 스무딩가 버킷팅 후에 적용됩니다:
- 샘플링
- 그룹화
- 표현식
- 비단조 x축
- 시간 기반 x축
다음은 이 동작이 내부적으로 어떻게 구현되는지 보여주는 예제 코드입니다:
data.forEach(d => {
const nextVal = d;
last = last * smoothingWeight + (1 - smoothingWeight) * nextVal;
numAccum++;
debiasWeight = 1.0 - Math.pow(smoothingWeight, numAccum);
smoothedData.push(last / debiasWeight);